资产收集的一些设想与实践
现在很多扫描器都可以进行资产收集,有没有想过将资产入库方便检索和查询呢?
W12Scan在当初设计的时候就有“资产”的概念,就是将数据库中的数据按照一定规则提取出来,同时根据提取的一些信息展示一些图表啥的。后面又觉得,一些漏洞信息,基础信息都要设计一个字段来存储,太浪费了,所以模仿threakbook引入了标签的概念,一些基础信息Server,Title,CMS的都可以当作为一个标签,漏洞信息也可以当作一个标签,而标签可以由程序自动添加也可以由我们自己添加。
这样就很容易搜索到相同的标签的网站了,字段可以按照如下设计(Mysql Demo):
域名表
id int // 主键id
url varchar // 域名url
ip varchar // 域名解析后的IP
createAt int // 创建时间
updateAt int // 修改时间标签表
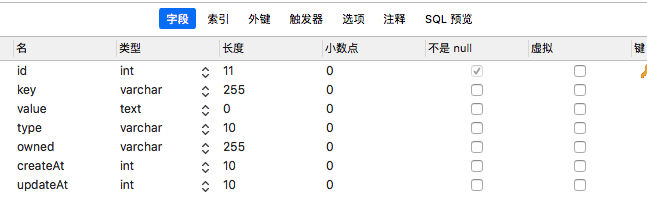
id主键,key为标签的名称;value标签内容;type标签类型,domain或ip;owned关联的是域名表中的url;createAt updateAt创建时间和修改时间。
然后通过一些程序主动搜集网络上的资产,Web类型搜集包括程序语言,waf,web服务器,使用框架,标题,操作系统,CMS等等。也可以从乌云的历史漏洞中解析出url,将url与乌云历史漏洞wooyun-id作为url的标签关联起来,将自己发现整理的信息也可以用标签的形式关联起来。
演示
这些想法原本是想用于w12scan上面的,但是自己的服务器跑不动w12scan,所以用php+mysql的架构将w10scan重写了下(主要是资产收集部分)。
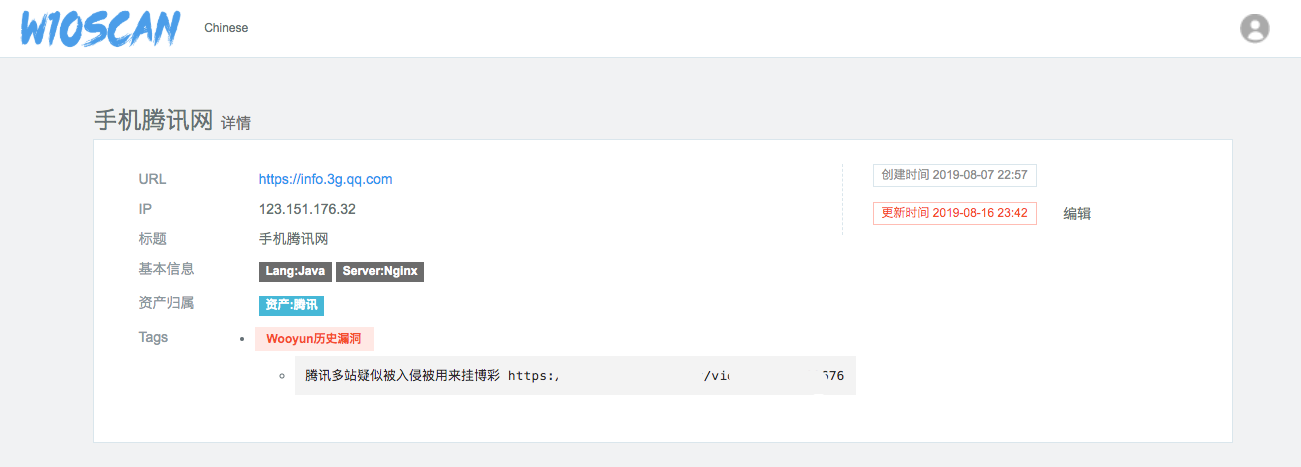
首先爬取了8w的乌云漏洞库,将其中的域名和地址抽离出来,存入了tag库,在搜索域名时,可以轻松看到该域名的历史漏洞了,然后加入了一些资产收集的程序做成了现在这个样子。
首页
资产管理
资产详情
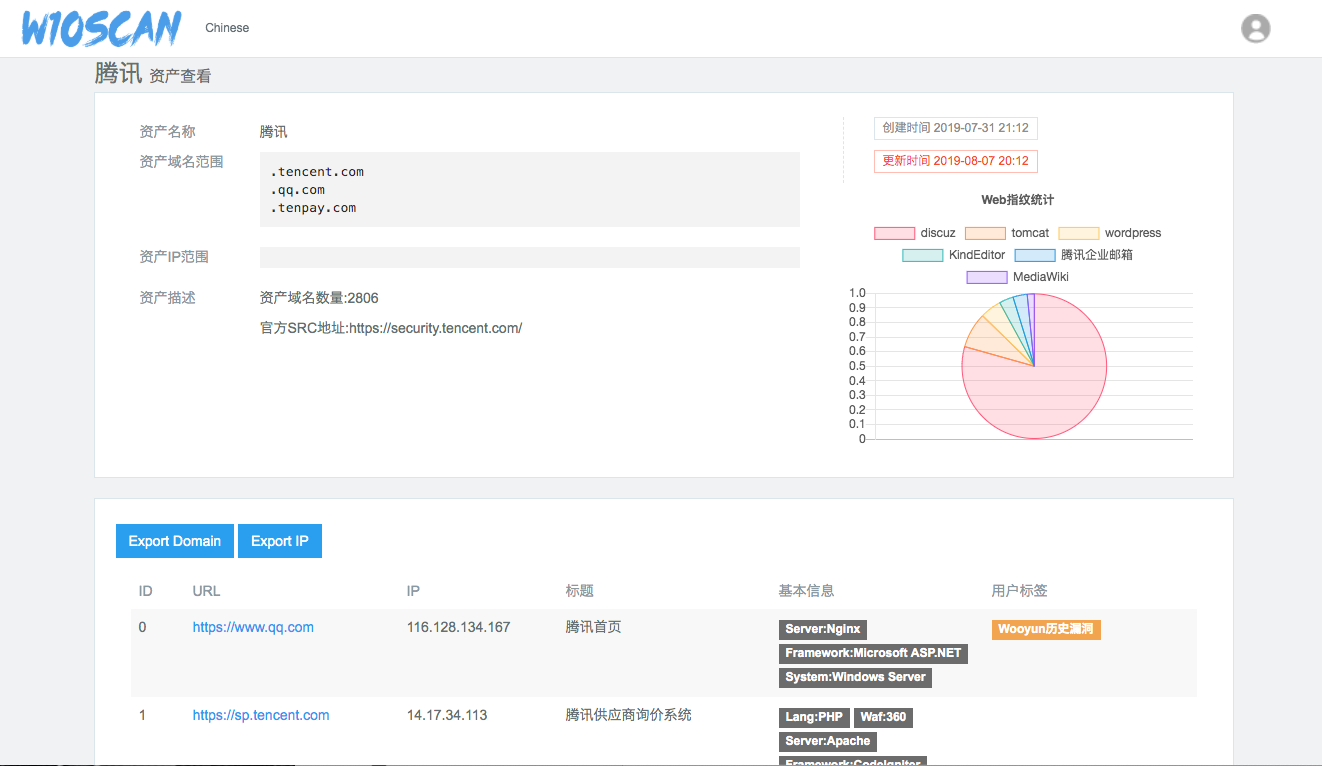
乌云漏洞关联
最后
提供一个抛砖引玉的思路,其中的具体设计还得自己实现,也可以参考我的w12scan~ https://github.com/w-digital-scanner/w12scan